
The Hamstring Crisis: Objective Testing Isn’t Objective—And That’s the Problem

In sport science, numbers are often mistaken for truth. The moment a force plate is placed under an athlete, many assume the result is objective, precise, and trustworthy. But the presence of technology does not guarantee the quality of the conclusion. Objectivity is not created by hardware. It is created by the discipline of the scientific process—by standardization, repeatability, methodological clarity, and the control of variables that distort what is being measured. When those standards are weak, the data may still look clean, but its meaning begins to collapse.

That is why this systematic review by Fahey and colleagues matters. It does more than summarize the current literature on single-joint posterior chain isometric testing using force plates. It reveals a deeper issue inside hamstring testing research: the field is still trying to draw confident conclusions from inconsistent methods. Across the literature, we see multiple test variations, inconsistent limb classifications, different verbal instructions, different sampling frequencies, and inconsistent approaches to reliability. That level of variation is not a small methodological detail. It is the central problem.
But there is a deeper layer that is rarely acknowledged—and it fundamentally challenges the assumption of what is actually being measured.
Knee flexion is not produced by a single muscle. It is the coordinated output of at least ten muscles, including the biceps femoris (long and short head), semitendinosus, semimembranosus, gracilis, sartorius, gastrocnemius (medial and lateral), plantaris, and popliteus. When an athlete produces force in a so-called “hamstring test,” the number that appears on the screen is not the output of one structure. It is the summed expression of a system.
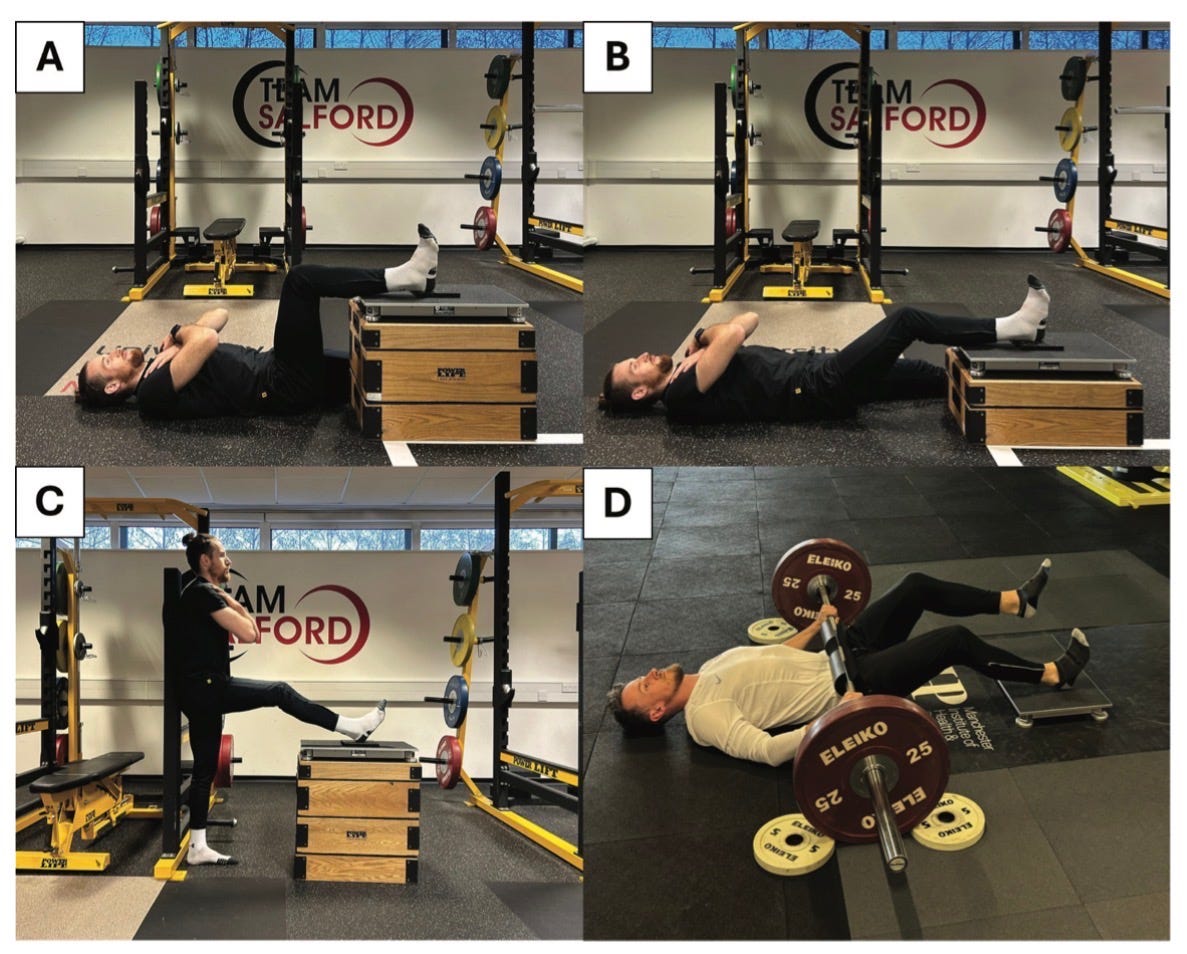
And we currently have no way—none—to determine, in real time, how much each of those muscles contributes to that total force.
So what are we actually measuring?
We are measuring the sum of unknown contributors.
Mathematically, this becomes clear. If total force is represented as:
f = x₁ + x₂ + x₃ … all the way to x₁₀
then each “x” represents the contribution of a different muscle within the system. Without the ability to isolate or quantify each variable independently, we are left with a single output that masks ten separate inputs. The moment we try to interpret that output as if it reflects a specific muscle—or even a consistent distribution of effort—we step into uncertainty.
Because the distribution of those contributions is not fixed.
It changes with joint angle. It changes with intent. It changes with fatigue. It changes with previous injury. It changes with neural strategy.
Two athletes can produce the same force output and arrive there through completely different neuromuscular solutions. Even the same athlete can produce the same number on different days using different internal strategies. From the outside, the data looks identical. Under the surface, it is not.
This is where the illusion of objectivity becomes most dangerous.
If we assume that a single force value represents a stable, repeatable, and specific muscular capacity, we are ignoring the complexity of the system that produced it. In reality, without the ability to distinguish each contributing variable, the probability of accurately interpreting that number approaches randomness more than certainty. The odds of correctly attributing that force to a specific structure or functional capacity are far closer to zero meaningful change than to 100% accuracy.
In practical terms, your odds of guessing what produced the number are not dramatically different from measuring it without proper context.
That does not make force plate testing useless. It makes it incomplete.
And when that incomplete data is layered on top of inconsistent methodology—different test positions, different instructions, different sampling rates, different analysis methods—the problem compounds. Now we are not only measuring a complex system as a single value, we are doing it under conditions that are not standardized.
The result is data that appears precise, but is highly sensitive to how it was created.
Peak force may appear reliable, but what does it actually represent? Rapid force metrics may fluctuate, but are they reflecting the athlete—or the method? Asymmetry scores may change, but are they physiological—or procedural?
These are not academic questions. They are applied decisions.
Because in performance environments, these numbers are used to guide training, influence rehabilitation, and shape return-to-play timelines. When the underlying assumptions are unstable, the decisions built on top of them become unstable as well.
The path forward is not to abandon testing. It is to elevate the standard.
We need tighter control of methodology. We need consistency in setup and instruction. We need clarity in what each metric can—and cannot—tell us. And most importantly, we need to respect the difference between measuring output and understanding its origin.
Because until science can isolate and quantify the individual contributions within the system in real time, we are not measuring a muscle.
We are measuring a result.
And if we mistake that result for something more precise than it is, we are not increasing objectivity.
We are increasing confidence in an assumption.
Performance durability conversations should start with understanding how force is generated, distributed, and controlled across the entire system—not just how it appears on a screen. Because when you understand the system, you don’t just measure strength. You train it.
At Isophit, we help the world’s strongest, fastest, and most dominant athletes—and everyday people—to win more, hurt less, and age stronger.
Learn more at www.isophit.com
